神经网络的向前传播
- 该笔记基于《深度学习入门》而写,所以在python实践部分不会使用神经网络框架
- 这篇笔记的编写目的主要为便于回忆基础知识,并非教程
- python实践部分的会用docsify整理到个人github上
与前章的联系
- 感知机的缺陷
- 无法自动设定权重
- 神经网络的重要性质是它可以自动地从数据中学习到合适的权重参数
神经网络的例子
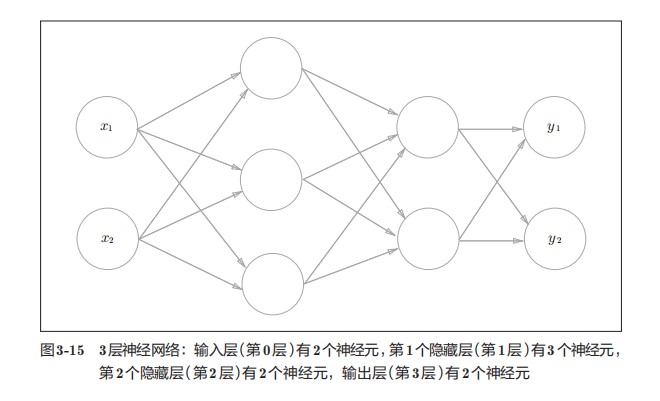
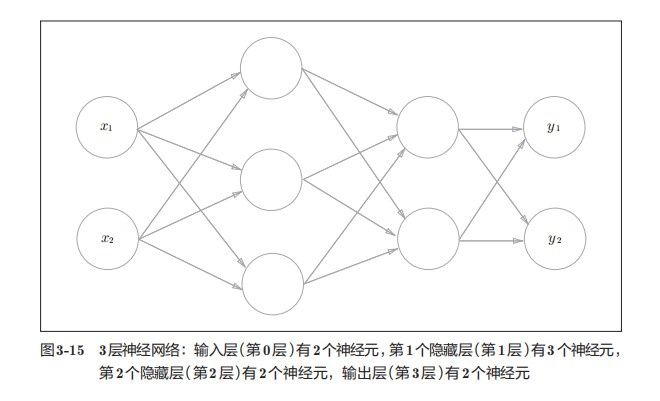
用图来表示神经网络的话,如图3-1所示。我们把最左边的一列称为输入层,最右边的一列称为输出层,中间的一列称为中间层。中间层有时也称为隐藏层。“隐藏”一词的意思是,隐藏层的神经元(和输入层、输出层不同)肉眼看不见。另外,把输入层到输出层依次称为第0层、第1层、第2层(层号之所以从0开始,是为了方便后面基于Python进行实现)。图3-1中,第0层对应输入层,第1层对应中间层,第2层对应输出层。
以上为感知机原理
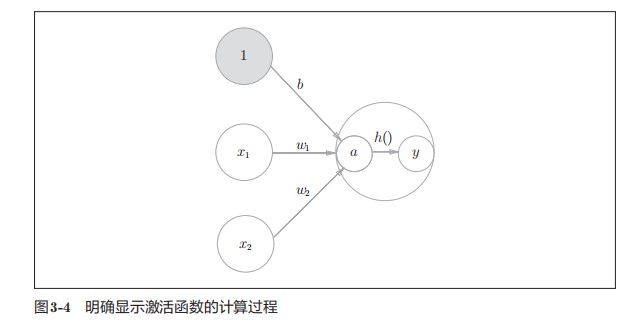
我们发现这个感知机将$x_1,x_2,1 $ 三个信号作为神经元的输入,将其和各自的权重相乘后,传送至下一个神经元。在下一个神经元中,计算这些加权信号的总和。如果这个总和超过0,则输出1,否则输出0
将这个式子改写成更加简洁的形式。并引入一个新函数$y=h(x)$将判断条件改成这个式子$y=h(b+\omega_1x_1+\omega_2x_2)$这样我们可以将判断语句简化成以下式子
如此一来通过h(x)函数可以将输入信号的总和转换为输出信号,同时我们也称这种函数为激活函数
激活函数
从上面来看
感知机使用了阶跃函数作为自己的激活函数
基础激活函数总结
- 阶跃函数
- sigmoid( )函数
- ReLu函数
- sigmoid( )函数
- ReLU函数
阶跃函数和sigmoid( )函数共同点:
下阶跃函数和sigmoid函数的共同性质。阶跃函数和sigmoid函数虽然在平滑性上有差异,但是如果从宏观视角看,可以发现它们具有相似的形状。实际上,两者的结构均是“输入小时,输出接近0(为0);随着输入增大,输出向1靠近(变成1)”。也就是说,当输入信号为重要信息时,阶跃函数和sigmoid函数都会输出较大的值;当输入信号为不重要的信息时,两者都输出较小的值。还有一个共同点是,不管输入信号有多小,或者有多大,输出信号的值都在0到1之间
神经网络的激活函数必须使用非线性函数,因为线性函数存在一个问题不管如何加深层数,总是存在与之等效的“无隐藏层的神经网络”。
比如说:
这里我们考虑把线性函数 h(x) = cx 作为激活函数,把y(x) = h(h(h(x)))的运算对应3层神经网络A。这个运算会进行y(x) =$c$ × $c$ x $c$ x $x$的乘法运算,但是同样的处理可以由y(x) = ax(注意,$a=c^{3}$)这一次乘法运算(即没有隐藏层的神经网络)来表示,无法发挥多层网络的优势,比如说不同权重的影响
书中bug:
求维度的应该是np.ndim
多维数组
基本是线代知识
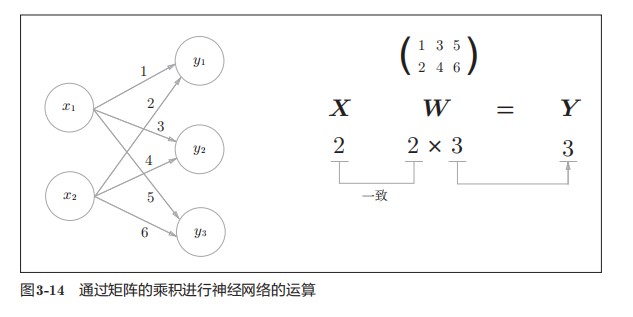
np.dot( )为矩阵乘法
神经网络的内积
1 | import numpy as np |
使用np.dot(多维数组的点积),可以一次性计算出Y 的结果。这意味着,即便Y 的元素个数为100或1000,也可以通过一次运算就计算出结果!如果不使用np.dot,就必须单独计算Y 的每一个元素(或者说必须使用for语句),非常麻烦。因此,通过矩阵的乘积一次性完成计算的技巧,在实现的层面上可以说是非常重要的。
书中的符号确定
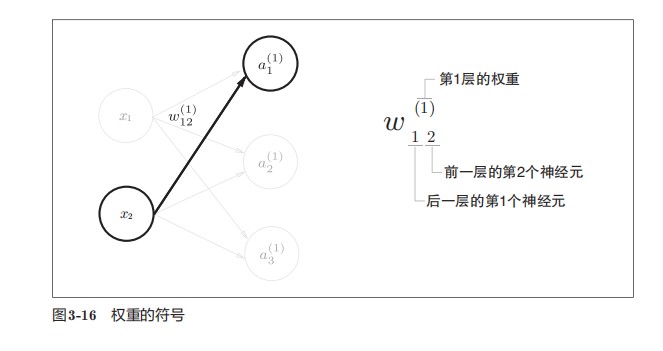
三层神经元的实现
以图3-15中的3层神经元为例子实现

个人更喜欢用类写,比较好分类
1 | import numpy as np |
输出层激活函数
机器学习的问题大致可以分为分类问题和回归问题。分类问题是数据属于哪一个类别的问题。比如,区分图像中的人是男性还是女性的问题就是分类问题。而回归问题是根据某个输入预测一个(连续的)数值的问题。比如,根据一个人的图像预测这个人的体重的问题就是回归问题(类似“57.4kg”这样的预测)。
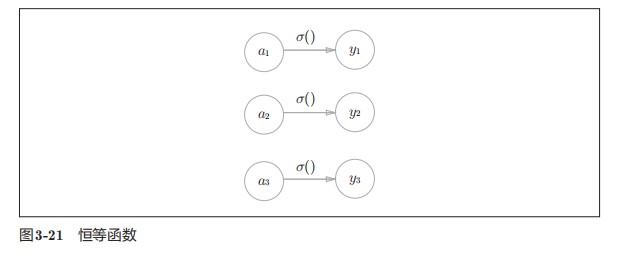
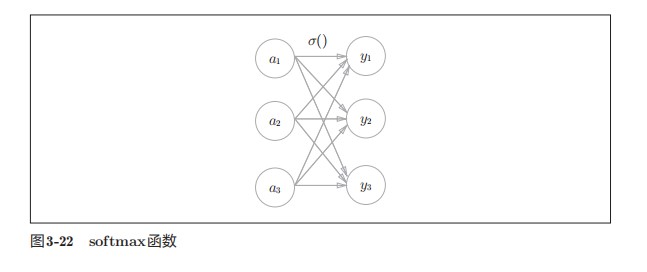
一般来说
- 回归问题可以用恒等函数
- 分类问题可以用softmax函数
softmax函数可以用以下数学式表示
softmax函数的特点:
在计算机的运算上有一定的缺陷。这个缺陷就是溢出问题。softmax函数的实现中要进行指数函数的运算,但是此时指数函数的值很容易变得非常大。如果在这些超大值之间进行除法运算,结果会出现“不确定”的情况。
应对策略:
在做exp( )直接先加个常数c防止溢出
softmax函数的输出是0.0到1.0之间的实数。并且,softmax函数的输出值的总和是1。输出总和为1是softmax函数的一个重要性质。可以把softmax函数的输出解释为“概率”。
因为指数函数(y = exp(x))是单调递增函数,a的各元素的大小关系和y的各元素的大小关系并没有改变。比如,a的最大值是第2个元素,y的最大值也仍是第2个元素。
一般而言,神经网络只把输出值最大的神经元所对应的类别作为识别结果。并且,即便使用softmax函数,输出值最大的神经元的位置也不会变。因此,神经网络在进行分类时(推理阶段),输出层的softmax函数可以省略。在实际的问题中,由于指数函数的运算需要一定的计算机运算量,因此输出层的softmax函数一般会被省略。
求解机器学习的问题可以分为两类:学习(有些地方也叫训练),推理
就像人一样先学习后实践
输出层的神经元数量
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。比如,对于某个输入图像,预测
是图中的数字0到9中的哪一个的问题(10类别分类问题),可以将输出层的神经元设定为10个。
MNIST数据集(实战—推理阶段)(先当权重训练好了)
书中可能用到的mnist.py会在另一个笔记(神经网络-mist.py注释)中写出,
如果为了于书中演示代码一致,推荐在运行代码的目录中建立一个名为dataset的文件夹,并把mnist.py放入里面
已经训练好的权重文件放在github上了
本笔记中的实践代码为本人魔改,本人就不按他的来,直接放在运行代码的根目录下
MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。
- 因为是灰度图片,所以它的像素值为灰度值,像素值范围为0-255
- 所以进行图像规一化时会直接除以255
- 因为是灰度图片,所以它的像素值为灰度值,像素值范围为0-255
因为是由784个像素构成的灰度手写数字图片,所以我们首先想到输入层为784个神经元组成,输出层为10个神经元构成
隐藏层的神经元可以设置成任意数目,但不保证效果…..
mnist数据集前期测试和处理
load_mnist函数以“(训练图像 ,训练标签 ),(测试图像,测试标签 )”的形式返回读入的MNIST数据。
normalize:图像的正规化
flatten:是否展开输入图像
one_hot_label:
设置是否将标签保存为one-hot表示(one-hot representation)。one-hot表示是仅正确解标签为1,其余皆为0的数组,就像[0,0,1,0,0,0,0,0,0,0]这样。当one_hot_label为False时,只是像7、2这样简单保存正确解标签;当one_hot_label为True时,标签则保存为one-hot表示。
测试代码:
1 | import sys,os |
显示MNIST图像
PIL中的Image
fromarry(obj)函数
Creates an image memory from an object exporting the array interface
(using the buffer protocol).
show()方法
显示使用show方法的对象的图片
1 | from mnist import load_mnist |
神经网络的推理过程(python实现)
1 | import numpy as np |
以上可以优化的地方
我们可以用批处理来实现更快速的推理
批处理对计算机的运算大有利处,可以大幅缩短每张图像的处理时间。那么为什么批处理可以缩短处理时间呢?这是因为大多数处理数值计算的库都进行了能够高效处理大型数组运算的最优化。并且,在神经网络的运算中,当数据传送成为瓶颈时,批处理可以减轻数据总线的负荷(严格地讲,相对于数据读入,可以将更多的时间用在计算上)。也就是说,批处理一次性计算大型数组要比分开逐步计算各个小型数组速度更快。
批处理下的python代码
1 | x, t = get_data() |


